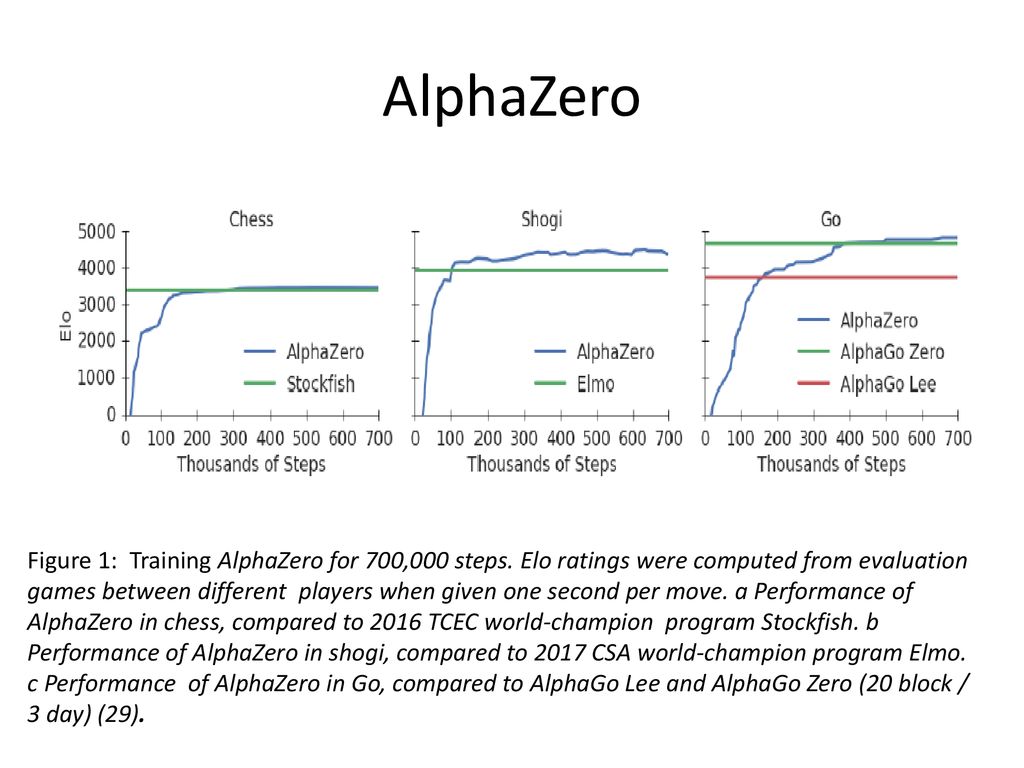
AlphaGo Zero Explained
Por um escritor misterioso
Last updated 15 abril 2025
Mastering the Game of Go without Human Knowledge

Deep Mind's AlphaGo Zero - EXPLAINED
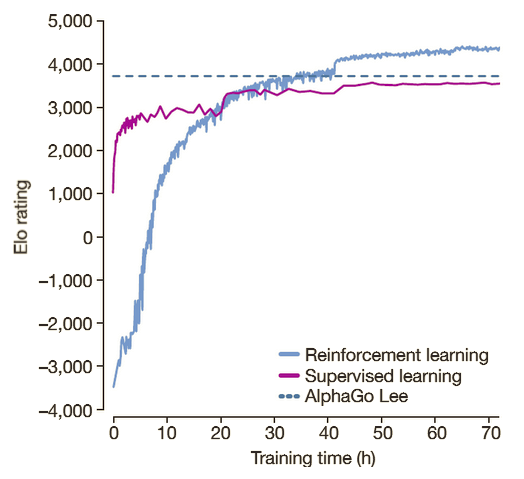
Self-play reinforcement learning in AlphaGo Zero. a The program plays a

Why DeepMind AlphaGo Zero is a game changer for AI research

neural network - AlphaGo Zero board evaluation function uses multiple time steps as an input Why? - Stack Overflow

AlphaGo and AlphaGo Zero

AlphaGo Zero Is Not A Sign of Imminent Human-Level AI – Skynet Today
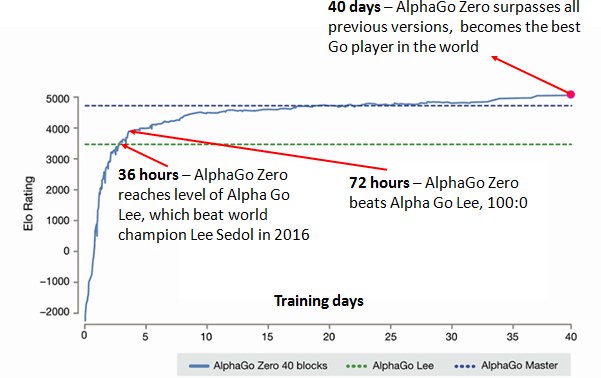
Alpha Go && Alpha Go Zero / Habr

AlphaGo Zero Explained In One Diagram, by David Foster, Applied Data Science

Reinforcement learning explained

Move 37: Artificial Intelligence, Randomness, and Creativity
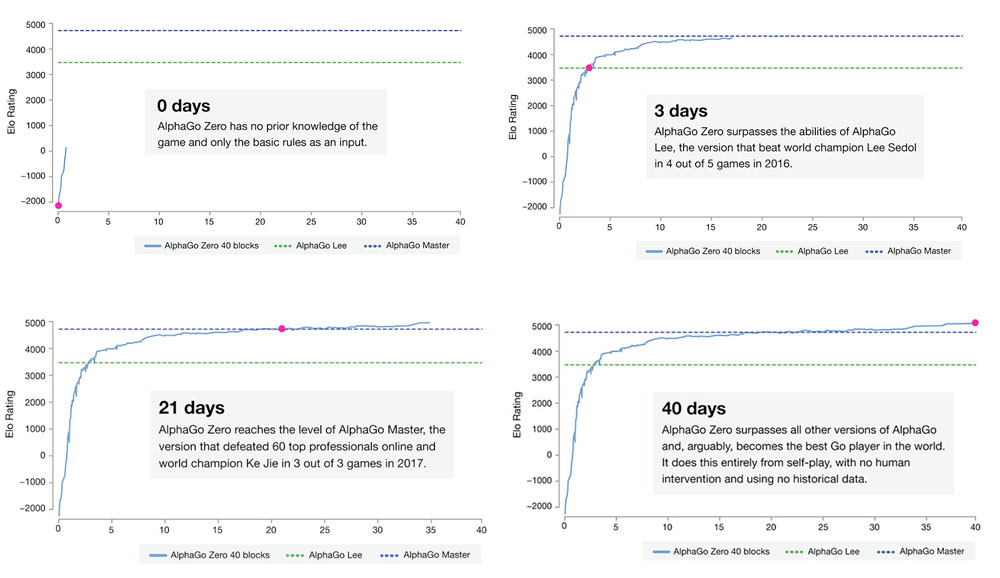
With Innovative Gaming Moves, Google's AI Becomes Go Grandmaster in 3 Days - The New Stack
Recomendado para você
-
![OC] AI vs human chess Elo ratings over time : r/dataisbeautiful](https://preview.redd.it/ai-vs-human-chess-elo-ratings-over-time-v0-mxub9uu5riia1.png?auto=webp&s=820677614c29eed64441b13cd4db08927decff01) OC] AI vs human chess Elo ratings over time : r/dataisbeautiful15 abril 2025
OC] AI vs human chess Elo ratings over time : r/dataisbeautiful15 abril 2025 -
 AlphaZero Chess Engine: The Ultimate Guide15 abril 2025
AlphaZero Chess Engine: The Ultimate Guide15 abril 2025 -
![PDF] Monte-Carlo Graph Search for AlphaZero](https://d3i71xaburhd42.cloudfront.net/4bafaf654937500f1a6a7c0df9c4f548f1c27e78/8-Figure5-1.png) PDF] Monte-Carlo Graph Search for AlphaZero15 abril 2025
PDF] Monte-Carlo Graph Search for AlphaZero15 abril 2025 -
 AlphaZero Defeats Stockfish 15.1 with 40000 Elo Performance with 4000 Elo Chess : r/PromoteGamingVideos15 abril 2025
AlphaZero Defeats Stockfish 15.1 with 40000 Elo Performance with 4000 Elo Chess : r/PromoteGamingVideos15 abril 2025 -
 From Zero to Master in Hours: AlphaZero Accelerates Reinforcement Learning15 abril 2025
From Zero to Master in Hours: AlphaZero Accelerates Reinforcement Learning15 abril 2025 -
 chess-alpha-zero/readme.md at master · Zeta36/chess-alpha-zero · GitHub15 abril 2025
chess-alpha-zero/readme.md at master · Zeta36/chess-alpha-zero · GitHub15 abril 2025 -
 ELO Ratings Benchmark (Game of Shogi)15 abril 2025
ELO Ratings Benchmark (Game of Shogi)15 abril 2025 -
 What is the theoretical Elo of AlphaGo? - Quora15 abril 2025
What is the theoretical Elo of AlphaGo? - Quora15 abril 2025 -
 Function approximation - ppt download15 abril 2025
Function approximation - ppt download15 abril 2025 -
![AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]](https://dfzljdn9uc3pi.cloudfront.net/2022/cs-1123/1/fig-4-full.png) AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]15 abril 2025
AlphaDDA: strategies for adjusting the playing strength of a fully trained AlphaZero system to a suitable human training partner [PeerJ]15 abril 2025
você pode gostar
-
 Resumo da novela A Regra do Jogo: Juliano descobre que Zé Maria é o pai da15 abril 2025
Resumo da novela A Regra do Jogo: Juliano descobre que Zé Maria é o pai da15 abril 2025 -
 Seven Knights Idle Adventure Codes December 2023: Free Rubies, Gold Coins & Rewards15 abril 2025
Seven Knights Idle Adventure Codes December 2023: Free Rubies, Gold Coins & Rewards15 abril 2025 -
 EPISÓDIO 01 ao 15 ANIME WAR Legendado PT-BR15 abril 2025
EPISÓDIO 01 ao 15 ANIME WAR Legendado PT-BR15 abril 2025 -
 Black Crop Tops for Girls Women Witchy Clothes Cute Shirts Concert Outfits Kawaii Goth Top Y2k T-Shirt Emo Alt Aesthetic at Women's Clothing store15 abril 2025
Black Crop Tops for Girls Women Witchy Clothes Cute Shirts Concert Outfits Kawaii Goth Top Y2k T-Shirt Emo Alt Aesthetic at Women's Clothing store15 abril 2025 -
 my pfp Funny cute cats, Funny cat wallpaper, Cat aesthetic15 abril 2025
my pfp Funny cute cats, Funny cat wallpaper, Cat aesthetic15 abril 2025 -
 NOVO JOGO SENSACIONAL PARA PS4 / XBOX ONE / PC I JOGO DE15 abril 2025
NOVO JOGO SENSACIONAL PARA PS4 / XBOX ONE / PC I JOGO DE15 abril 2025 -
 Tonikaku Kawaii - Anime revela Novos Membros do Elenco — ptAnime15 abril 2025
Tonikaku Kawaii - Anime revela Novos Membros do Elenco — ptAnime15 abril 2025 -
 61+ HD & Free Aesthetic Wallpapers for Professionals15 abril 2025
61+ HD & Free Aesthetic Wallpapers for Professionals15 abril 2025 -
Grandmaster's Fisherman Garb — Loot and prices — Albion Online 2D Database15 abril 2025
-
 Concept Masterline Batman: Arkham City Batman15 abril 2025
Concept Masterline Batman: Arkham City Batman15 abril 2025