Move over AlphaGo: AlphaZero taught itself to play three different games
Por um escritor misterioso
Last updated 24 abril 2025

DeepMind's new AI is worthy successor to the first program to beat a human at Go.
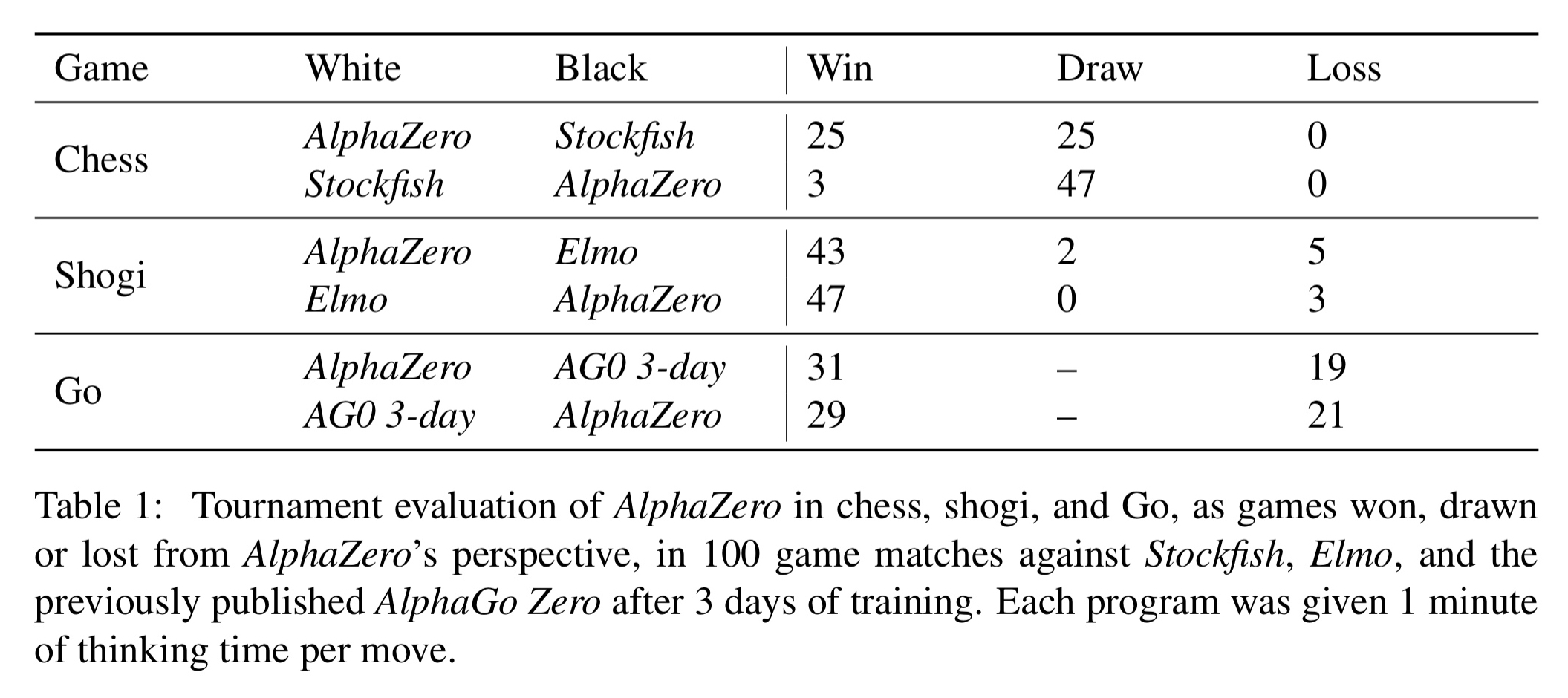
Mastering chess and shogi by self-play with a general reinforcement learning algorithm
/pic4082863.png)
Designer Diary: The Search for AlphaMystica, GEEK Digital Board Games
Self-play reinforcement learning in AlphaGo Zero. a The program plays a

AlphaZero: Shedding new light on chess, shogi, and Go - Google DeepMind

Simple Alpha Zero

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

Acquisition of chess knowledge in AlphaZero
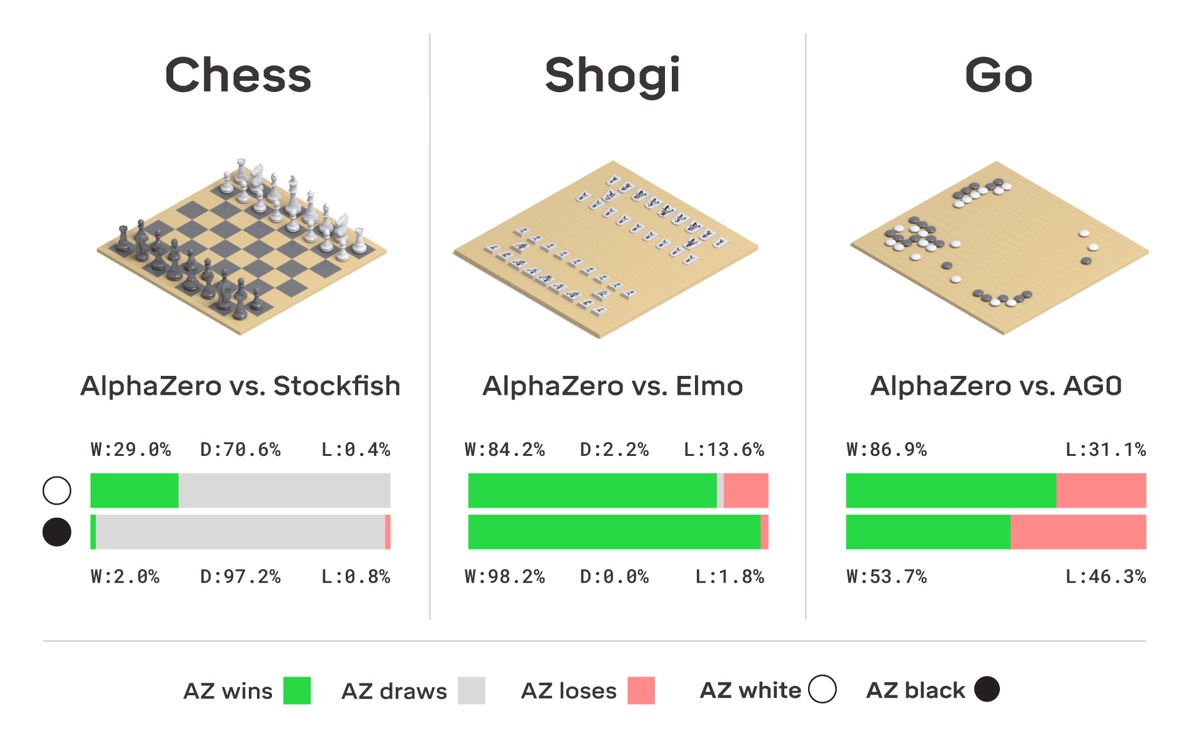
Move over AlphaGo: AlphaZero taught itself to play three different games

AlphaZero

It's able to create knowledge itself': Google unveils AI that learns on its own, Science
Recomendado para você
-
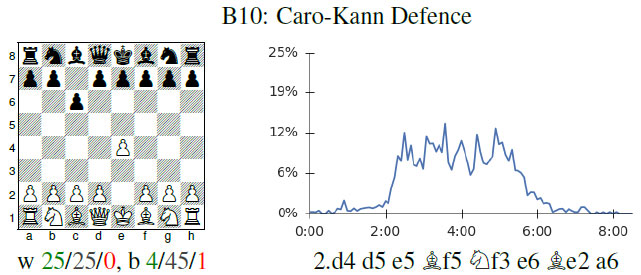 The future is here – AlphaZero learns chess24 abril 2025
The future is here – AlphaZero learns chess24 abril 2025 -
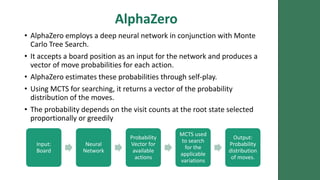 AlphaZero Vs StockFish – A Literature Review.pptx24 abril 2025
AlphaZero Vs StockFish – A Literature Review.pptx24 abril 2025 -
![AlphaGo Zero] Mastering the game of Go without human knowledge](https://i.ytimg.com/vi/_x9bXso3wo4/sddefault.jpg) AlphaGo Zero] Mastering the game of Go without human knowledge24 abril 2025
AlphaGo Zero] Mastering the game of Go without human knowledge24 abril 2025 -
 PDF) The Next Rembrandt Surveils AlphaZero: An AI Lover Story Entangling Machine Cognition24 abril 2025
PDF) The Next Rembrandt Surveils AlphaZero: An AI Lover Story Entangling Machine Cognition24 abril 2025 -
 DeepMind: the existence proof for RL at scale, by Nathan Lambert24 abril 2025
DeepMind: the existence proof for RL at scale, by Nathan Lambert24 abril 2025 -
 PDF) AlphaZero-What's Missing?24 abril 2025
PDF) AlphaZero-What's Missing?24 abril 2025 -
 Alpha Scholars24 abril 2025
Alpha Scholars24 abril 2025 -
 Alpha Zero one Multi-Collagen Powder 100g-grass fed24 abril 2025
Alpha Zero one Multi-Collagen Powder 100g-grass fed24 abril 2025 -
 A general reinforcement learning algorithm that masters chess24 abril 2025
A general reinforcement learning algorithm that masters chess24 abril 2025 -
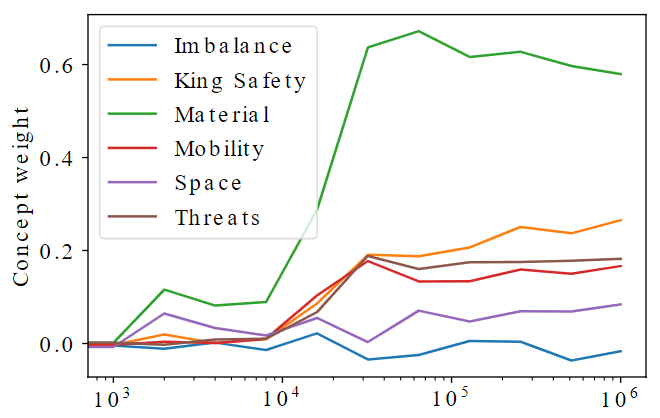 How AlphaZero Learns Chess?. DeepMind and Google Brain researchers…, by Gayan Samuditha, Expo-MAS24 abril 2025
How AlphaZero Learns Chess?. DeepMind and Google Brain researchers…, by Gayan Samuditha, Expo-MAS24 abril 2025
você pode gostar
-
 Harley Quinn Crazy Toys Arlequina Figures Roupas Reais 30cm24 abril 2025
Harley Quinn Crazy Toys Arlequina Figures Roupas Reais 30cm24 abril 2025 -
 sapphics like on X in 2023 Chloe grace moretz, Chloe grace24 abril 2025
sapphics like on X in 2023 Chloe grace moretz, Chloe grace24 abril 2025 -
 Máquina Virtual Pronta Para Rodar Lol - League Of Legends - DFG24 abril 2025
Máquina Virtual Pronta Para Rodar Lol - League Of Legends - DFG24 abril 2025 -
 One Piece: Episode of Luffy - Adventure on Hand Island (TV Movie24 abril 2025
One Piece: Episode of Luffy - Adventure on Hand Island (TV Movie24 abril 2025 -
 MOJE RŮZNÉ RPG POSTAVY - Camp Half-Blood RPG - Wattpad24 abril 2025
MOJE RŮZNÉ RPG POSTAVY - Camp Half-Blood RPG - Wattpad24 abril 2025 -
 Dragonball Evolution (2009) Poster #2 - Trailer Addict24 abril 2025
Dragonball Evolution (2009) Poster #2 - Trailer Addict24 abril 2025 -
kumalala kumalala savesta - Apps on Google Play24 abril 2025
-
 Quebra-cabeça de xadrez - Jogue Online em SilverGames 🕹24 abril 2025
Quebra-cabeça de xadrez - Jogue Online em SilverGames 🕹24 abril 2025 -
 Natasha Panda24 abril 2025
Natasha Panda24 abril 2025 -
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2022/y/g/RfAMNmSpaymWATAfWsyg/ddf.png) Aplicativo Play Premiado é golpe? Saiba como funciona app e se é seguro24 abril 2025
Aplicativo Play Premiado é golpe? Saiba como funciona app e se é seguro24 abril 2025
