RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari
Por um escritor misterioso
Last updated 11 abril 2025

In this issue, we look at MuZero, DeepMind’s new algorithm that learns a model and achieves AlphaZero performance in Chess, Shogi, and Go and achieves state-of-the-art performance on Atari. We also look at Safety Gym, OpenAI’s new environment suite for safe RL.
RL Weekly 35: Escaping Local Optimas in Distance-based Rewards and Choosing the Best Teacher
RL Weekly

Home

Scheduling UAV Swarm with Attention-based Graph Reinforcement Learning for Ground-to-air Heterogeneous Data Communication

PDF) OCAtari: Object-Centric Atari 2600 Reinforcement Learning Environments

Uncategorized – Severely Theoretical
Home

PDF) Alpha-T: Learning to Traverse over Graphs with An AlphaZero-inspired Self-Play Framework

PDF) Mastering Atari Games with Limited Data

Scheduling UAV Swarm with Attention-based Graph Reinforcement Learning for Ground-to-air Heterogeneous Data Communication
RL Weekly 9: Sample-efficient Near-SOTA Model-based RL, Neural MMO, and Bottlenecks in Deep Q-Learning : r/reinforcementlearning

PDF) OCAtari: Object-Centric Atari 2600 Reinforcement Learning Environments

Mastering Atari Games with Limited Data – arXiv Vanity
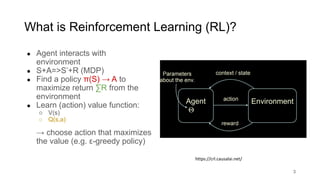
Memory for Lean Reinforcement Learning.pdf
Recomendado para você
-
AlphaZero_Connect4/README.md at master · plkmo/AlphaZero_Connect411 abril 2025
-
GitHub - gemasphi/alpha-zero-torch: a clean generic alpha zero11 abril 2025
-
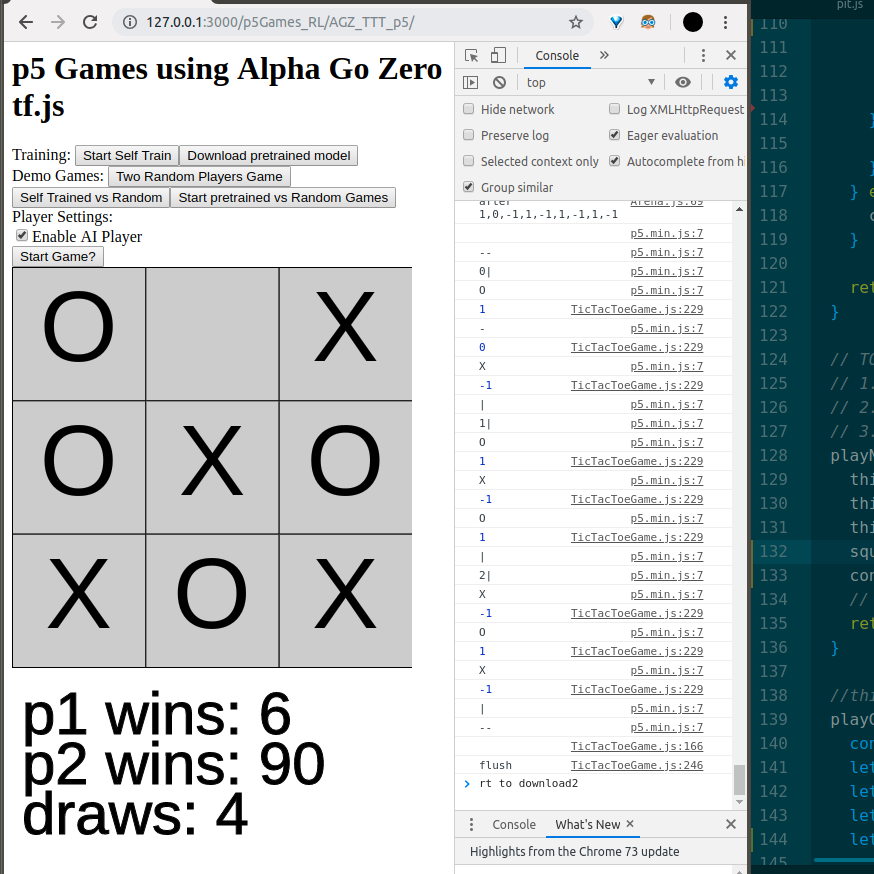 Alpha Zero General playing Tic Tac Toe in p5 using tf.js — J11 abril 2025
Alpha Zero General playing Tic Tac Toe in p5 using tf.js — J11 abril 2025 -
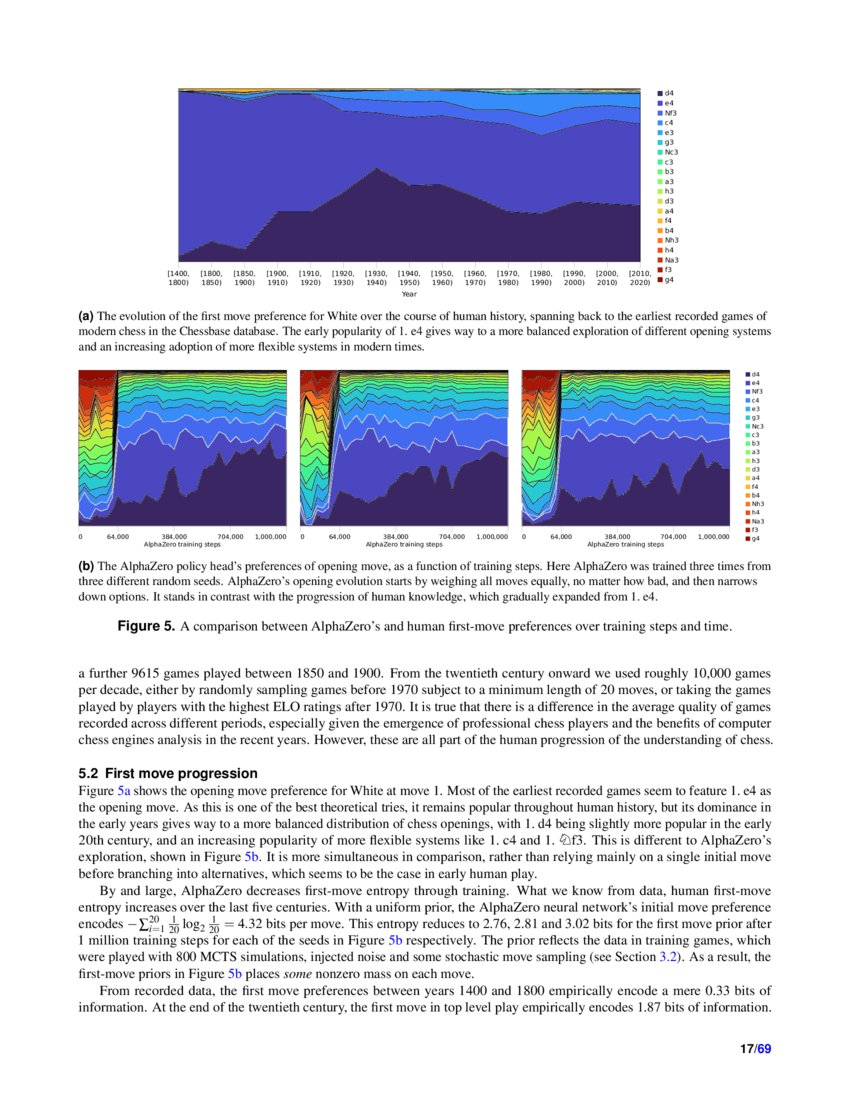 Acquisition of Chess Knowledge in AlphaZero11 abril 2025
Acquisition of Chess Knowledge in AlphaZero11 abril 2025 -
AlphaZero like implementation for Oware Abapa game - AlphaZero11 abril 2025
-
 MuZero - Notes on AI11 abril 2025
MuZero - Notes on AI11 abril 2025 -
 AlphaZero - Chessprogramming wiki11 abril 2025
AlphaZero - Chessprogramming wiki11 abril 2025 -
alphazero (Joubin Houshyar) · GitHub11 abril 2025
-
 GitHub - pytorch/ELF: ELF: a platform for game research11 abril 2025
GitHub - pytorch/ELF: ELF: a platform for game research11 abril 2025 -
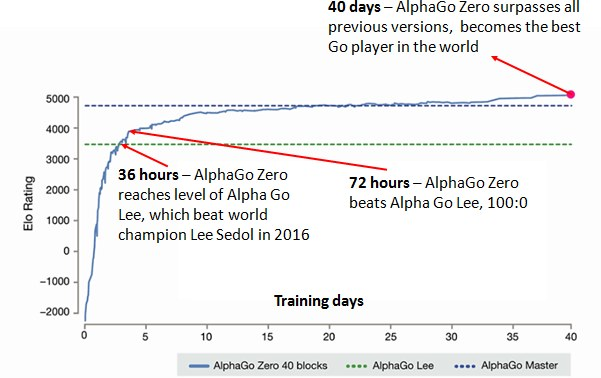 How to build your own AlphaZero AI using Python and Keras11 abril 2025
How to build your own AlphaZero AI using Python and Keras11 abril 2025

você pode gostar
-
 Thor: Love and Thunder': What's Lowering Its Rotten Tomatoes Score11 abril 2025
Thor: Love and Thunder': What's Lowering Its Rotten Tomatoes Score11 abril 2025 -
 Berserk Um anime que você precisa assistir.11 abril 2025
Berserk Um anime que você precisa assistir.11 abril 2025 -
 Fiorentina Femminile players celebrate the goal during ACF Fiorentina femminile vs Inter, Italian Soccer Serie A Women Championship, Florence, Italy Stock Photo - Alamy11 abril 2025
Fiorentina Femminile players celebrate the goal during ACF Fiorentina femminile vs Inter, Italian Soccer Serie A Women Championship, Florence, Italy Stock Photo - Alamy11 abril 2025 -
 Tanjuro Kamado, Kimetsu no Yaiba Wiki11 abril 2025
Tanjuro Kamado, Kimetsu no Yaiba Wiki11 abril 2025 -
 Desenhos Antigos 80 Desenhos antigos, Desenhos animados clássicos, Melhores gatos11 abril 2025
Desenhos Antigos 80 Desenhos antigos, Desenhos animados clássicos, Melhores gatos11 abril 2025 -
 Poderes da Magu Magu no Mi A fruta de Akainu (One Piece)11 abril 2025
Poderes da Magu Magu no Mi A fruta de Akainu (One Piece)11 abril 2025 -
 Everyone's talking about rip_indra-chan, but. : r/bloxfruits11 abril 2025
Everyone's talking about rip_indra-chan, but. : r/bloxfruits11 abril 2025 -
 Why Kids Love Bounce Parks So Much11 abril 2025
Why Kids Love Bounce Parks So Much11 abril 2025 -
 Dog Clicker Pet Sound Trainer Dog Training Clicker Pet Trainer Clicker Dog Toy Clicker - Temu11 abril 2025
Dog Clicker Pet Sound Trainer Dog Training Clicker Pet Trainer Clicker Dog Toy Clicker - Temu11 abril 2025 -
 Croatian league football match between Rijeka and Hajduk Split, Stadion Poljud, Split, Dalmatia, Croatia Stock Photo - Alamy11 abril 2025
Croatian league football match between Rijeka and Hajduk Split, Stadion Poljud, Split, Dalmatia, Croatia Stock Photo - Alamy11 abril 2025