XQuAD Dataset Papers With Code
Por um escritor misterioso
Last updated 22 abril 2025

XQuAD (Cross-lingual Question Answering Dataset) is a benchmark dataset for evaluating cross-lingual question answering performance. The dataset consists of a subset of 240 paragraphs and 1190 question-answer pairs from the development set of SQuAD v1.1 (Rajpurkar et al., 2016) together with their professional translations into ten languages: Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, and Hindi. Consequently, the dataset is entirely parallel across 11 languages.

PDF] CodeQA: A Question Answering Dataset for Source Code

SberQuAD Dataset Papers With Code
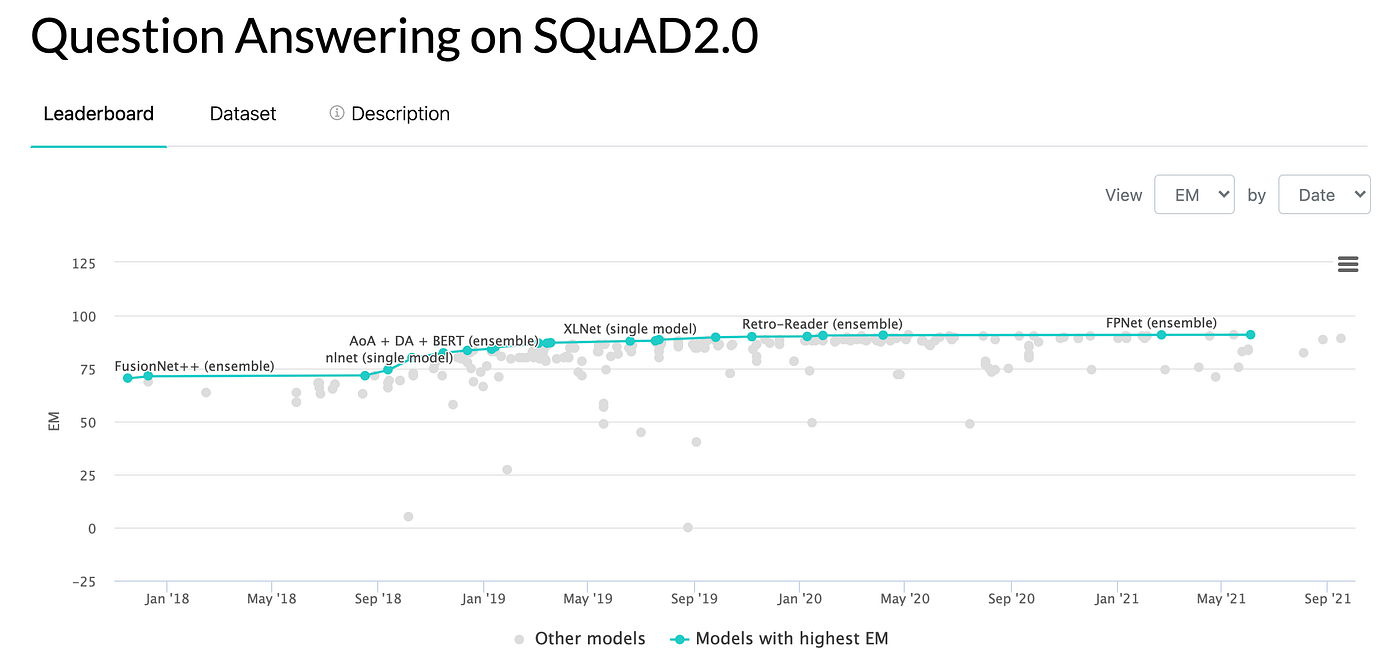
How to Answer Questions with Machine Learning

SQuAD model sentence relation and deep semantics error
End to End Question-Answering System Using NLP and SQuAD Dataset

Disfl-QA: A Benchmark Dataset for Understanding Disfluencies in

UAVVaste Dataset Papers With Code

Nlakh Dataset Papers With Code

Top Viewed Papers Referred by ArXiv

CovidQA Dataset Papers With Code
Recomendado para você
-
250 TOP I.C. Engines - Mechanical Engineering Multiple Choice Questions and Answers List, PDF, Internal Combustion Engine22 abril 2025
-
 Internal Combustion Engines 2010-2011 BE Mechanical Engineering Semester 6 (TE Third Year) Old question paper with PDF download22 abril 2025
Internal Combustion Engines 2010-2011 BE Mechanical Engineering Semester 6 (TE Third Year) Old question paper with PDF download22 abril 2025 -
 SOLUTION: Automobile engineering multiple choice questions - Studypool22 abril 2025
SOLUTION: Automobile engineering multiple choice questions - Studypool22 abril 2025 -
 STCW_Test_-Answers_Report_Management Questions and answers., Exams Health sciences22 abril 2025
STCW_Test_-Answers_Report_Management Questions and answers., Exams Health sciences22 abril 2025 -
![PDF] ME6016 Advanced I.C. Engines (AICE) Books, Lecture Notes, 2marks with answers, Important Part B 16marks Questions, Question Bank & Syllabus – EasyEngineering](https://i0.wp.com/easyengineering.net/wp-content/uploads/2017/07/advance-ic-engines-219x300.jpg?resize=219%2C300) PDF] ME6016 Advanced I.C. Engines (AICE) Books, Lecture Notes, 2marks with answers, Important Part B 16marks Questions, Question Bank & Syllabus – EasyEngineering22 abril 2025
PDF] ME6016 Advanced I.C. Engines (AICE) Books, Lecture Notes, 2marks with answers, Important Part B 16marks Questions, Question Bank & Syllabus – EasyEngineering22 abril 2025 -
 CDL Test Flashcards Questions and Answers Already Passed22 abril 2025
CDL Test Flashcards Questions and Answers Already Passed22 abril 2025 -
.jpg) Marine Notes: Lamb's Questions and Answers on Marine Diesel Engine by marinenotes22 abril 2025
Marine Notes: Lamb's Questions and Answers on Marine Diesel Engine by marinenotes22 abril 2025 -
 115 Question and Answers DMV Test (Latest 2022/2023) Download to Score A, Exams Engineering22 abril 2025
115 Question and Answers DMV Test (Latest 2022/2023) Download to Score A, Exams Engineering22 abril 2025 -
 Steam Turbine Interview Question Answer Pdf - Colaboratory22 abril 2025
Steam Turbine Interview Question Answer Pdf - Colaboratory22 abril 2025 -
![CDL Test Questions and Answers Latest [100% correct answers] - CDL - Stuvia US](https://www.stuvia.com/docpics/3201798/64d02e67d3cbf_3201798_1200_1700.webp) CDL Test Questions and Answers Latest [100% correct answers] - CDL - Stuvia US22 abril 2025
CDL Test Questions and Answers Latest [100% correct answers] - CDL - Stuvia US22 abril 2025

você pode gostar
-
 Doom Patrol temporada 4: assista todos os episódios na HBO Max22 abril 2025
Doom Patrol temporada 4: assista todos os episódios na HBO Max22 abril 2025 -
 Homem careca de meia-idade segurando uma bola de basquete sobre22 abril 2025
Homem careca de meia-idade segurando uma bola de basquete sobre22 abril 2025 -
 IGN's Top Mods for Overhauling Fallout: New Vegas22 abril 2025
IGN's Top Mods for Overhauling Fallout: New Vegas22 abril 2025 -
 Kazan - Character (116630) - AniDB22 abril 2025
Kazan - Character (116630) - AniDB22 abril 2025 -
 Digging for Gold Mining Stocks22 abril 2025
Digging for Gold Mining Stocks22 abril 2025 -
 Bully Android Apk Award - taleshoff22 abril 2025
Bully Android Apk Award - taleshoff22 abril 2025 -
anime da escola de bruxa|TikTok Arama22 abril 2025
-
 Fullmetal Alchemist: The Downfall of Van Hohenheim22 abril 2025
Fullmetal Alchemist: The Downfall of Van Hohenheim22 abril 2025 -
 bolo de aniversario tema moto22 abril 2025
bolo de aniversario tema moto22 abril 2025 -
 Demon Slayer Season 3 Episode 11 Review : r/Animeexplores22 abril 2025
Demon Slayer Season 3 Episode 11 Review : r/Animeexplores22 abril 2025
