PDF] Mastering Chess and Shogi by Self-Play with a General
Por um escritor misterioso
Last updated 15 abril 2025
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://d3i71xaburhd42.cloudfront.net/38fb1902c6a2ab4f767d4532b28a92473ea737aa/5-Table1-1.png)
This paper generalises the approach into a single AlphaZero algorithm that can achieve, tabula rasa, superhuman performance in many challenging domains, and convincingly defeated a world-champion program in each case. The game of chess is the most widely-studied domain in the history of artificial intelligence. The strongest programs are based on a combination of sophisticated search techniques, domain-specific adaptations, and handcrafted evaluation functions that have been refined by human experts over several decades. In contrast, the AlphaGo Zero program recently achieved superhuman performance in the game of Go, by tabula rasa reinforcement learning from games of self-play. In this paper, we generalise this approach into a single AlphaZero algorithm that can achieve, tabula rasa, superhuman performance in many challenging domains. Starting from random play, and given no domain knowledge except the game rules, AlphaZero achieved within 24 hours a superhuman level of play in the games of chess and shogi (Japanese chess) as well as Go, and convincingly defeated a world-champion program in each case.
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://d3i71xaburhd42.cloudfront.net/cf39c819dc1352c3da52d4d4c7dd3a23fb933e97/5-Table1-1.png)
PDF] Mastering Terra Mystica: Applying Self-Play to Multi-agent Cooperative Board Games
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://www.science.org/cms/asset/43c95308-f652-4574-a388-63b68cddfb48/362_1140_f1.gif)
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
What exactly makes the greatest players of all time, such as Magnus Carlsen, Bobby Fischer, and Garry Kasparov stand out from the rest? The basic
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://i.ytimg.com/vi/KVDoKNec9sQ/maxresdefault.jpg)
Mastering Chess Logic
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://www.furidamu.org/images/alphago_zero_cover.webp)
papers
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://i1.rgstatic.net/publication/321571298_Mastering_Chess_and_Shogi_by_Self-Play_with_a_General_Reinforcement_Learning_Algorithm/links/5b965e37a6fdccfd5439bf17/largepreview.png)
PDF) Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://0.academia-photos.com/attachment_thumbnails/84353697/mini_magick20220417-22811-sd3r.png?1650242535)
PDF) A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://d3i71xaburhd42.cloudfront.net/4c7028640e3470a73af84d22eafa78855931c70f/20-Figure2-1.png)
PDF] Giraffe: Using Deep Reinforcement Learning to Play Chess
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://www.researchgate.net/publication/343568113/figure/fig4/AS:923185167994883@1597115904708/Human-vs-Machine-in-Live-Play-with-Chess-Transformer-The-Colaboratory-notebook-includes_Q320.jpg)
PDF) The Chess Transformer: Mastering Play using Generative Language Models
![PDF] Mastering Chess and Shogi by Self-Play with a General](https://media.springernature.com/full/springer-static/image/art%3A10.1038%2Fnature24270/MediaObjects/41586_2017_Article_BFnature24270_Fig1_HTML.jpg)
Mastering the game of Go without human knowledge
Recomendado para você
-
 Checkmate: how we mastered the AlphaZero cover, Science15 abril 2025
Checkmate: how we mastered the AlphaZero cover, Science15 abril 2025 -
 Diversifying AI: Towards Creative Chess with AlphaZero15 abril 2025
Diversifying AI: Towards Creative Chess with AlphaZero15 abril 2025 -
![PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero](https://d3i71xaburhd42.cloudfront.net/1660a5d34d5fb237b8d64d292c4f360bc70252be/5-Figure1-1.png) PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero15 abril 2025
PDF] ELF OpenGo: An Analysis and Open Reimplementation of AlphaZero15 abril 2025 -
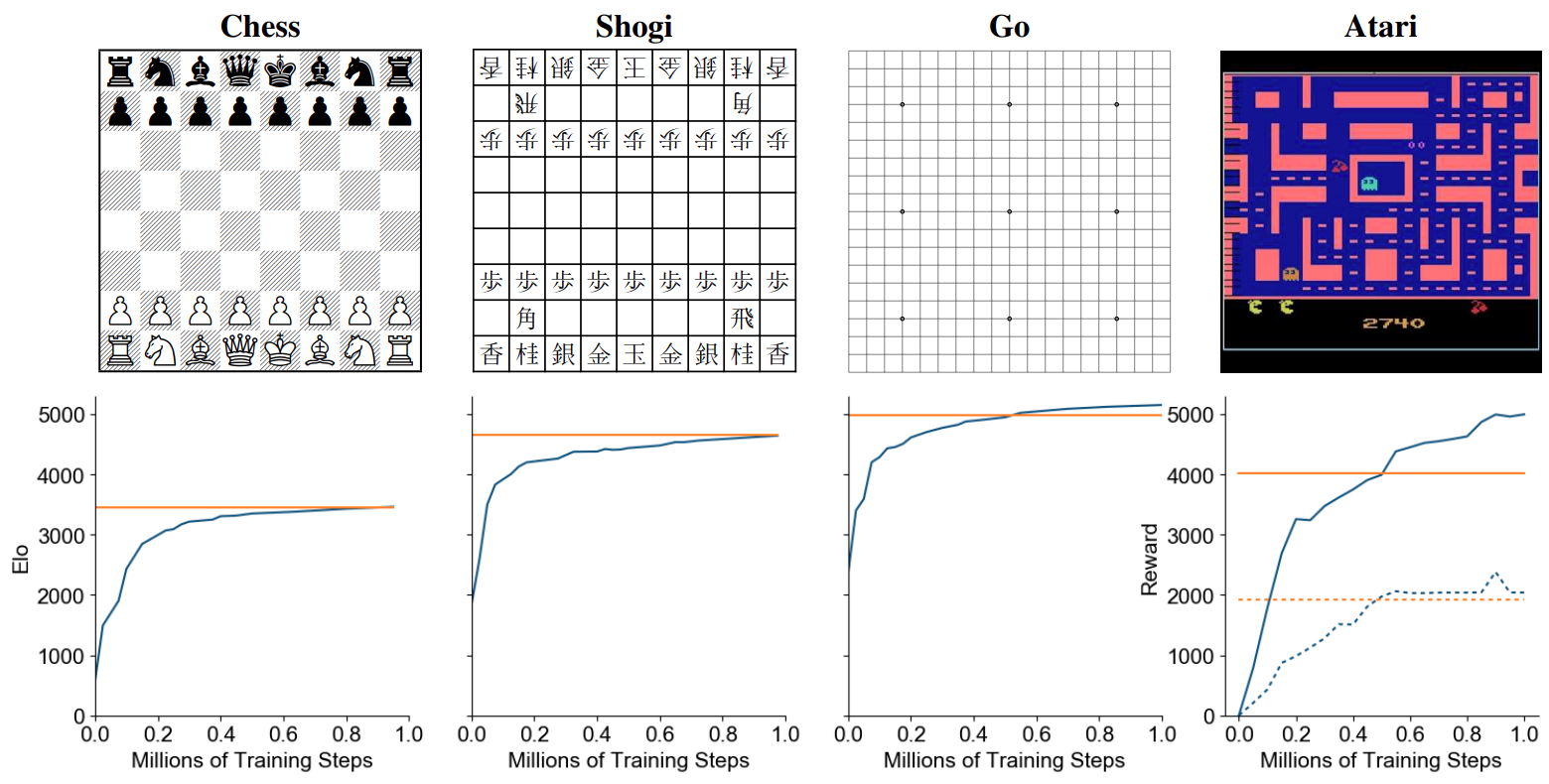 Simplifying MuZero in Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model — Andrew Silva15 abril 2025
Simplifying MuZero in Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model — Andrew Silva15 abril 2025 -
 Alpha S 2 Pickleball Paddle Bundle - Pickleball Paddle Shop15 abril 2025
Alpha S 2 Pickleball Paddle Bundle - Pickleball Paddle Shop15 abril 2025 -
 Genlab Alpha – Card Deck - Free League Publishing15 abril 2025
Genlab Alpha – Card Deck - Free League Publishing15 abril 2025 -
 PDF) AlphaZero-What's Missing?15 abril 2025
PDF) AlphaZero-What's Missing?15 abril 2025 -
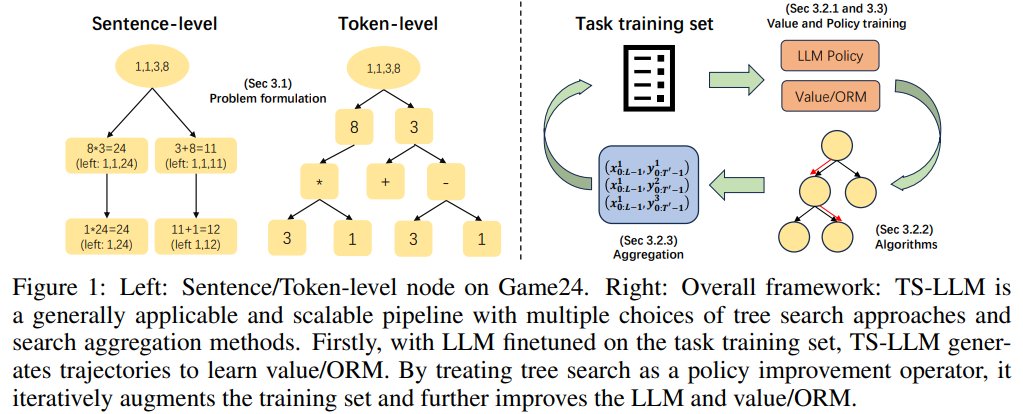 xidong feng on X: 🎉Excited to share our new work that tries to use AlphaZero-like tree search for LLM's decoding and training. We include a detailed pipeline and comprehensive experiments to show15 abril 2025
xidong feng on X: 🎉Excited to share our new work that tries to use AlphaZero-like tree search for LLM's decoding and training. We include a detailed pipeline and comprehensive experiments to show15 abril 2025 -
 How the Artificial Intelligence Program AlphaZero Mastered Its Games15 abril 2025
How the Artificial Intelligence Program AlphaZero Mastered Its Games15 abril 2025 -
 Move over AlphaGo: AlphaZero taught itself to play three different games15 abril 2025
Move over AlphaGo: AlphaZero taught itself to play three different games15 abril 2025
você pode gostar
-
 Tipo Boneca Bebê Baby Real Reborn Realista Bolsa + 28 Itens15 abril 2025
Tipo Boneca Bebê Baby Real Reborn Realista Bolsa + 28 Itens15 abril 2025 -
 Kit 10 Jogos de Dominó com Caixas em mdf Cru 3mm15 abril 2025
Kit 10 Jogos de Dominó com Caixas em mdf Cru 3mm15 abril 2025 -
 Five Nights at Freddy's VR: Help Wanted Poster by G011d3nPony10 on DeviantArt15 abril 2025
Five Nights at Freddy's VR: Help Wanted Poster by G011d3nPony10 on DeviantArt15 abril 2025 -
 Five Nights At Freddy's Trailer oficial da adaptação é divulgado15 abril 2025
Five Nights At Freddy's Trailer oficial da adaptação é divulgado15 abril 2025 -
 Psycho-Pirate - Wikipedia15 abril 2025
Psycho-Pirate - Wikipedia15 abril 2025 -
 Quiz sobre frações15 abril 2025
Quiz sobre frações15 abril 2025 -
 Friday The 13th Wallpaper Mobile - iXpap15 abril 2025
Friday The 13th Wallpaper Mobile - iXpap15 abril 2025 -
 Different eyes on each anime characters power15 abril 2025
Different eyes on each anime characters power15 abril 2025 -
Block Puzzle for Nintendo Switch - Nintendo Official Site15 abril 2025
-
 Red Dead Online Is Getting New Content Soon15 abril 2025
Red Dead Online Is Getting New Content Soon15 abril 2025
